В статье рассматривается создание автоматических отчетов в pull-requests, которые мы применяем в работе, чтобы обеспечить надежность разрабатываемых frontend-приложений.
Введение
Одна из популярных метрик кода — дубликация. Дубликация — это осознанное или неосознанное копирование идентичных фрагментов кода в разных контекстах. Кроме этого, фрагменты кода могут быть не идентичными, а весьма похожими: отличаться имена переменных или форматирование кода. Дубликация плоха тем, что снижается объем кода, который переиспользуется. Также, если была допущена ошибка в дубликате, то она содержится и в оригинальном фрагменте. И в случае исправления ошибки в таком коде, придется искать все места, где была допущена дубликация, а значит и ошибка. Это может привести к различным версиям одного и того же фрагмента кода, что еще сильнее усугубит проблему.
В командной работе важный этап — это контроль качества кода (code quality control), один из методов — это ревью кода (code review). Увы, кода и задач может быть много и не все пункты чек-листа по проверке кода ревьювер может проверить. Здесь помогает автоматизация проверок. В этой статье рассматривается такой механизм автоматизации проверок качества кода, как BitBucket Pipelines + Reports.
Процесс разработки, основанный на pull-requests заключается в том, что разработчик представляет протестированный и завершенный результат работы над задачей в виде pull-request — отдельной ветки в репозитории, которая готова к слиянию с основной веткой кода. Назначается один или большее количество ревьюверов, которые должны дать свое экспертное заключение о качестве кода, о способе решения задачи и принять решение: принять pull-request или отклонить его.
Создание собственного отчёта в информации о Pull-request
Одним из инструментов настройки и работы с репозиторием в Bitbucket является Code insights.
Code insights — возможность BitBucket Pull-request интерфейса, предоставить дополнительные отчеты, аннотации и просмотреть метрики, которые помогут улучшить качество кода в процессе его проверки в пулл-реквестах.
UI отчёт
Рассмотрим пример отчёта.
Все созданные собственные отчёты отображаются в пункте “n report” на вкладке “Details” меню Pull-request слева от его diff-а.
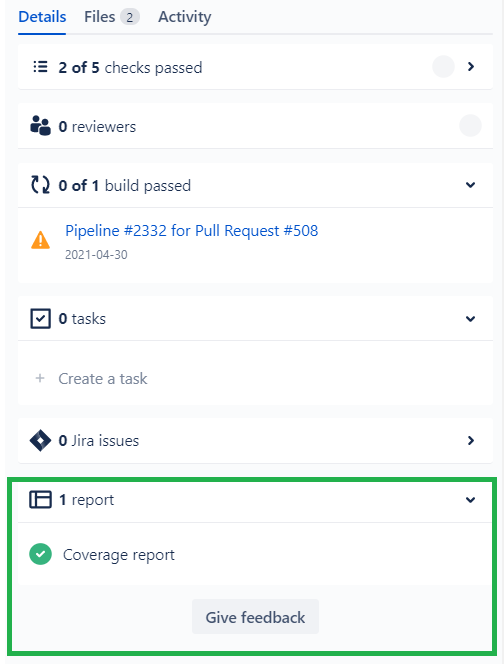
Сам отчёт выглядит следующим образом:
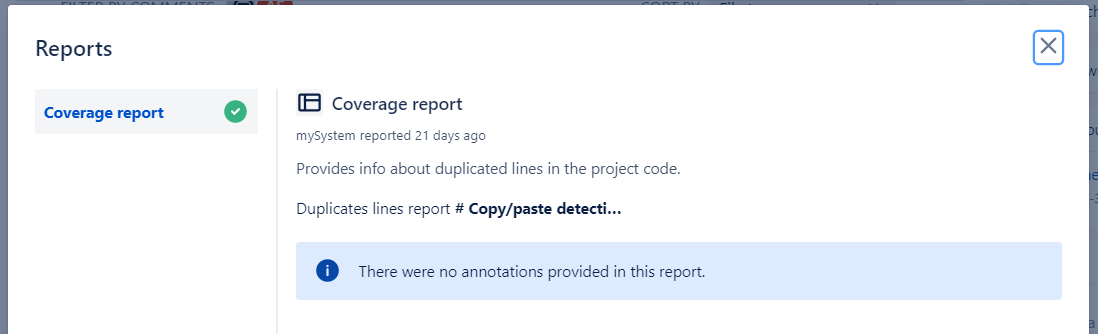
Замечание: Созданный отчёт — это драфтовая версия, поэтому вся информация отображается не совсем в нужном виде, а сам отчёт будет дорабатываться.
Механизм создания отчёта
В качестве тестового репорта рассмотрим информацию о дубликациях в коде. Для ее определения использовалась npm библиотека jscpd.
Для анализа дубликации в коде добавляем соответствующий шаг в BitBucket Pipeline-спецификацию и сохраняем результат проверки в артефакты — текстовые отчёты о результатах запуска шага.
- step:
name: 'Duplicates lines check'
script:
- npm i -g то jscpd
- jscpd --format "typescript" ./src/app --reporters markdown
artifacts:
- report/jscpd-report.mdДалее, для того чтобы выводить полученные данные в виде отчёта, используются API от Bitbucket:
GET /2.0/repositories/{workspace}/{repo_slug}/commit/{commit}/reportsи
PUT | GET | DELETE
2.0/repositories/{workspace}/{repo_slug}/commit/{commit}/reports/{reportId}</span>Для экспериментов мы будем использовать API создания и получения отчёта.
Рассмотрим ключевые операции API.
PUT /2.0/repositories/{workspace}/{repo_slug}/commit/{commit}/reports/{reportId}Позволяет создать или обновить отчёт для указанного коммита.
Для того, чтобы загрузить отчёт, необходимо выбрать сгенерирован уникальный для всех отчётов этого коммита идентификатор. В нашем случае был использован идентификатор из примера - mySystem-001.
Типы отчётов (report_type):
- SECURITY — информация о проблемах с безопасностью в коде;
- COVERAGE — информация о покрытии кода тестами;
- TEST — отчет о тестировании;
- BUG — обнаруженная ошибка в коде.
Виды состояний отчётов (result):
- PASSED — проверка прошла успешно;
- FAILED — проверка показала критические ошибки;
- PENDING — проверка в прогрессе.
data — это непосредственно список тех полей, которые будут отображаться в репорте. Максимально разрешенное количество: 10.
Разрешенные типы:
- BOOLEAN — флаг true/false;
- DATE — дата;
- DURATION — длительность;
- LINK — ссылка;
- NUMBER — число;
- PERCENTAGE — процент;
- TEXT — свободный текст.
Следует заметить, что информация, передаваемая в data должна иметь незначительное количеством символов по размеру, например, “true”, “123%”, “ok” и т.п. Иначе она может не поместиться в отведенном месте:

Помимо данных выше в репорте также можно указать: title репорта, назначение/цель (details), ссылку на репорты сторонних сервисов (link), логотип (logo), даты создания (created_on) и обновления (updated_on).
Bitbucket позволяет делать вызовы API локально и в Pipeline. Чтобы использовать второй вариант - необходимо “заполнить” запрос нужными переменными окружения (environment variables) контейнера:
- До
/2.0/repositories/{workspace}/{repo_slug}/commit/{commit}/reports/{reportId</span>- После
/2.0/repositories/$BITBUCKET_REPO_OWNER/$BITBUCKET_REPO_SLUG/commit/$BITBUCKET_COMMIT/reports/mySystem-001,</span>О назначении всех ключей можно узнать в документации.
Пример Python-скрипта для формирования payload-объекта, где жирным выделена ключевая функция для формирования структуры payload:
import json
import sys
def bitbucket_report_generator(c: str) -> dict:
d1 = {"title": "Duplicates lines report", "type": "TEXT", "value": c}
d = {
"title": "Coverage report",
"details": "Provides info about duplicated lines in the project code.",
"report_type": "COVERAGE",
"reporter": "mySystem",
"result": "PASSED",
"data": [
d1
]
}
return d
def bitbucket_report_saver(c: str, f: str):
d = bitbucket_report_generator(c)
with open(f, 'w') as f2:
json.dump(d, f2)
if __name__ == '__main__':
if len(sys.argv) < 3:
print ('Expected two params: CONTENT FILENAME')
exit(-1)
content = sys.argv[1]
filename = sys.argv[2]
bitbucket_report_saver(content, filename)Использование Reports-API предполагает дополнительную аутентификацию. Для того, чтобы этого не делать, необходимо было отправлять запросы через прокси-сервер, который работает вместе с каждым pipeline на «localhost:29418». Тогда к запросу автоматически добавляется валидный Auth-Header.
В результате всех действий получаем следующий вариант curl и фрагмент YAML-конфигурации BitBucket Pipelines:
- content=$(cat report/jscpd-report.md)
- export CONTENT="${content}"
- python3 bitbucket_report_saver.py "$CONTENT" output.json
- >
curl --proxy 'http://localhost:29418' \
--request PUT "http://api.bitbucket.org/2.0/repositories/$BITBUCKET_REPO_OWNER/$BITBUCKET_REPO_SLUG/commit/$BITBUCKET_COMMIT/reports/mySystem-001" \
--header 'Content-Type: application/json' \
--data "@output.json"Результат выполнения шага с curl-запросом в BitBucket Pipelines:
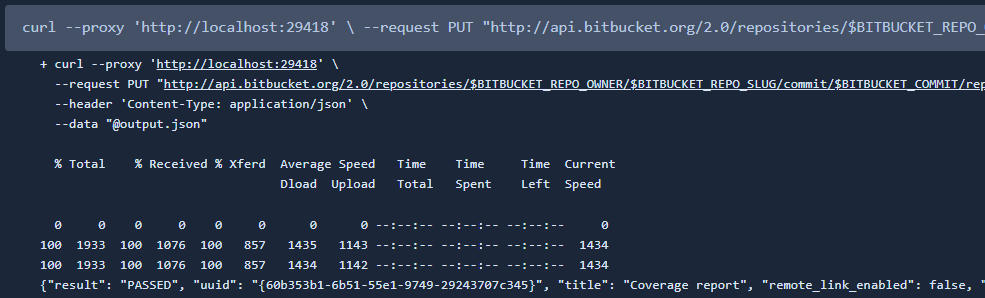
GET /2.0/repositories/{workspace}/{repo_slug}/commit/{commit}/reportsПозволяет получить список репортов, которые связаны с текущим коммитом.
Это API было использовано в качестве эксперимента и, по-сути, никак не влияет на процесс создания репорта. Однако ниже можно увидеть пример curl и вид в pipeline.
curl --proxy 'http://localhost:29418' --request GET \
"http://api.bitbucket.org/2.0/repositories/$BITBUCKET_REPO_OWNER/$BITBUCKET_REPO_SLUG/commit/$BITBUCKET_COMMIT/reports"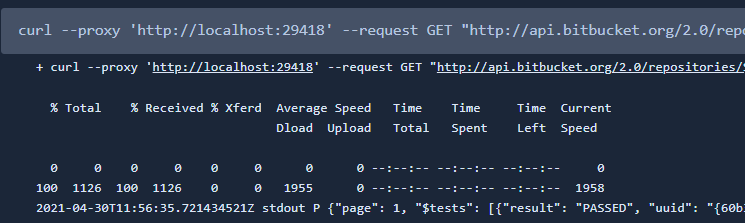
В совокупности нужные шаги YAML-конфигурации BitBucket Pipelines для создания репорта выглядят следующим образом:
- step:
name: 'Duplicates lines check'
script:
- npm i -g jscpd
- jscpd --format "typescript" ./src/app --reporters markdown
artifacts:
- report/jscpd-report.md
- step:
name: 'Report creating'
script:
- content=$(cat report/jscpd-report.md)
- export CONTENT="${content}"
- python3 bitbucket_report_saver.py "$CONTENT" output.json
- >
curl --proxy 'http://localhost:29418' \
--request PUT
"http://api.bitbucket.org/2.0/repositories/$BITBUCKET_REPO_OWNER/$BITBUCKET_REPO_SLUG/commit/$BITBUCKET_COMMIT/reports/mySystem-001" \
--header 'Content-Type: application/json' \
--data "@output.json"
- >
curl --proxy 'http://localhost:29418' --request GET \
"http://api.bitbucket.org/2.0/repositories/$BITBUCKET_REPO_OWNER/$BITBUCKET_REPO_SLUG/commit/$BITBUCKET_COMMIT/reports"Заключение (выводы)
Ревью кода на предмет функциональных и нефункциональных ошибок на этапе pull-requests — ключевой этап для обеспечения процесса надежной разработки ПО. Чтобы помочь ревьюверу объективно и быстро оценить качество кода целесообразно автоматизировать проверки.
В данной статье показана автоматизация одной проверки — поиск дупликации в коде. Объем дубликации нужно держать на минимуме, при повышении уровня дупликации необходимо рассмотреть рефакторинги, которые исправляют этот недостаток.
В перспективе можно добавить и другие отчеты. Например:
— покрытие кода тестами;
— сообщения линтеров и статических анализаторов;
— сообщения security-сканнеров.
Об авторах

Анастасия Смирнова
Frontend Software Engineer в Design and Test Lab
Технический редактор: Владимир Обризан, к. т. н., директор в Design and Test Lab.